



Широко используемая до последнего времени реляционная модель данных оказывается недостаточно эффективной при решении задач построения информационных систем с повышенной нагрузочной способностью [1], в частности, ориентированных на хранение значительного количества записей, одновременную обработку запросов от большого числа пользователей и т.п. Это обуславливает актуальность поиска альтернативных моделей данных, преодолевающих указанные недостатки.
Общепринято классифицировать логические модели представления данных (баз данных), по трём основным видам: реляционные, иерархические и сетевые. К реляционным относятся логические модели в виде изменяющихся во времени наборов отношений; к иерархическим - логические модели в виде древовидной структуры; к сетевым - в виде произвольного графа. Следует отметить, что разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков. Исходя из этого, будем рассматривать иерархическую модель представления данных как частный случай сетевой модели.
С технической точки зрения можно выделить два аргумента в пользу замещения реляционной модели данных иерархической моделью:
1. Возможность построения эффективно функционирующих систем, рассчитанных на большой объем хранимых данных (от 10 млн записей и более); в реляционных базах подобного размера использование ключей для агрегирующих функций, как правило, приводит к существенному увеличению времени выполнения операций обработки данных.
2. Наличие гибких возможностей масштабирования приложения путем распределения нагрузки на несколько вычислительных комплексов или сетей без существенных материально-временных затрат; в реляционных базах стоимость расширения, содержания и поддержки, как правило, оказывается запретительно высокой.
Рассмотрим структуру иерархической базы данных (рисунок, а). Здесь представлена трехуровневая структура данных, отражающая иерархическую модель. Следует отметить, что в корневом элементе хранятся ключи доступа ко всем служебным наборам данных. На следующем уровне располагаются наборы данных, содержащие ключи от наборов данных конечных пользователей.
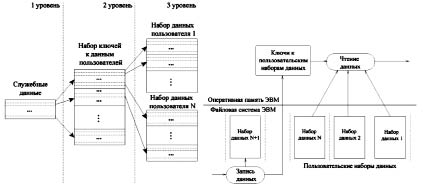
а б
Структура иерархической базы данных и схема её работы
Как показано на рисунок, б организация доступа ко всем таблицам пользователей будет ограничена только скоростью операций ввода-вывода вычислительной машины. Временем, затрачиваемым на поиск данных конечного пользователя можно пренебречь, исходя из того, что ключ от требуемого набора данных всегда доступен для оперативной памяти. При добавлении нового пользовательского набора данных ключ добавляется в хранилище пользовательских ключей, а в файловую систему ЭВМ добавляется новая запись. Таким образом, обеспечивается непрерывная работа информационной системы, постоянное обновление ключей к пользовательским наборам данных и обеспечение целостности данных.
Подобная организация логической модели представления данных позволяет обеспечить распределение нагрузки по обработке запросов пользователя между несколькими вычислительными машинами, так как система хранения и записываемые наборы данных не привязаны одной базе данных.
Исходя из рассмотренной схемы работы иерархической модели данных, можно сделать следующие выводы:
1. Высокая доступность данных - все элементы в дерева данных доступны в любой момент для конечного пользователя.
2. Дополнительная масштабирование - информационная модель с иерархической структурой может быть распределена между несколькими информационными сис-
темами.
3. Низкая стоимость содержания высоконагруженной информационной системы на основе иерархической модели данных по сравнению с традиционной моделью.
Рассмотренный подход был применён при миграции системы управления просмотром текстовых SMS-сообщений, исходно реализованной с применением MySQL Server, в СУБД иерархического типа. Реализованное программное обеспечение позволяет эффективно поддерживать базу объёмом ~300 млн записей, ориентированную на работу с более 1000 пользователями.
Список литературы
1. Khetrapal A., Ganesh V. HBase and Hypertable for large scale distributed storage Systems // Dept. of Computer Science, Purdue University. - 2008. - C. 1-6.
Библиографическая ссылка
Котов В.В., Лобанов Н.В. ПРОЕКТИРОВАНИЕ ВЫСОКОНАГРУЖЕННЫХ ИНФОРМАЦИОННЫХ СИСТЕМ НА БАЗЕ ИЕРАРХИЧЕСКИХ МОДЕЛЕЙ ДАННЫХ // Успехи современного естествознания. – 2011. – № 4. – С. 159-161;URL: https://natural-sciences.ru/ru/article/view?id=21207 (дата обращения: 19.04.2024).