



В задачах интегрирования баз данных часто возникает проблема оценки сходства объектов [1]. В большинстве случаев такого рода оценка сходства может базироваться на некоторых семантических характеристиках объектов [2]. Так, например, наиболее примитивной семантической характеристикой атрибутов отношений можно считать тип атрибута. Однако при интегрировании комплексных баз данных, такой характеристики недостаточно. Возникает проблема разработки более сложных семантических характеристик атрибутов, на базе которых в дальнейшем можно разрабатывать меры сходства объектов баз данных. В данной работе будет предложена семантическая характеристика атрибутов отношений на базе строковых шаблонов.
Шаблон - общеизвестный образец, трафарет. Шаблоны используются для сжатого описания некоторого множества объектов, без необходимости перечисления всех экземпляров этого множества.
Пусть дано множество объектов (экземпляров) некоторого типа. Пусть на этом множестве заданы правила определения шаблонов и язык шаблонов L - это формальный язык определения шаблонов. Каждый шаблон ![]() определяет набор экземпляров
определяет набор экземпляров ![]() , которые удовлетворяют данному шаблону. Множество
, которые удовлетворяют данному шаблону. Множество ![]() является подмножеством множества всех возможных экземпляров U [3].
является подмножеством множества всех возможных экземпляров U [3].
Опишем синтаксис и структуру шаблонов, которые будем использовать для описания строковых данных. Разобьем символы в иерархически упорядоченные группы (см. рис. 1).
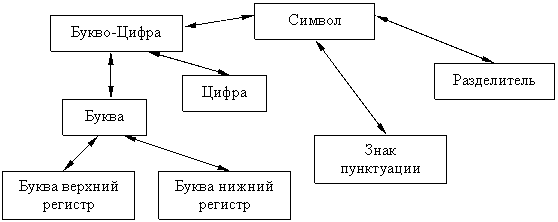
Рис. 1. Иерархия символов строкового шаблона.
В квадратных скобках будем обозначать группы символов, которые могут присутствовать на текущей позиции строки. Например [а, б, в] - множество букв а, б, в. Конструкция вида [а, б, в]{n, m} - означает, что символы а, б, в встречаются в количество от n до m. Конструкция вида [а, б, в]{n, } - означает, что символы а, б, в встречаются в количество не менее n. Конструкция вида [а, б, в]{ , m} - означает, что символы а, б, в встречаются в количество не более m. Отметим, что в квадратных скобках может так же присутствовать некоторый шаблон, который в данном случае будем называть подшаблоном.
Для удобства использования и в соответствии с рисунком 1 введем следующие обозначения групп символов:
![]() - множество букв нижнего регистра: [а, б, в, ..., я];
- множество букв нижнего регистра: [а, б, в, ..., я];
![]() - множество букв верхнего регистра: [А, Б, В, ..., Я];
- множество букв верхнего регистра: [А, Б, В, ..., Я];
![]() - множество любых символов;
- множество любых символов;
![]() - множество букв [а, б, в, ... , я, А, Б, В, ... , Я];
- множество букв [а, б, в, ... , я, А, Б, В, ... , Я];
![]() - множество цифр [0, 1, 2, ... , 9];
- множество цифр [0, 1, 2, ... , 9];
![]() - множество букв и цифр;
- множество букв и цифр;
![]() - знак пунктуации [!, ", #, $, %, &, ´, (, ), *, +, ,, -, ., /, :, ;, <, =, >, ?, @, [, , ], ^, _, `, {, |, }, ~];
- знак пунктуации [!, ", #, $, %, &, ´, (, ), *, +, ,, -, ., /, :, ;, <, =, >, ?, @, [, , ], ^, _, `, {, |, }, ~];
![]() - множество разделителей [ ,
, f,
, s];
- множество разделителей [ ,
, f,
, s];
Как было показано выше, любой шаблон определяет некоторое множество строк. И можно считать, что данный шаблон является некоторым семантическим описанием этого множества строк. Очевидно, что один шаблон не может полностью описать все семантические особенности данного множества строк, однако некоторую семантическую значимость шаблон, безусловно, несет. С одной стороны шаблон тем лучше описывает множество строк, чем больше строк из этого множества удовлетворяют шаблону. С другой стороны шаблон тем лучше описывает множество строк, чем больше строк, не принадлежащих данному множеству, не удовлетворяют этому шаблону. Семантической значимостью можно считать некоторую обобщенную численную оценку, удовлетворяющую указанным выше свойствам. Можно так же предположить, что при определенных условиях некоторое множество шаблонов в совокупности будет иметь семантическую значимость для множества строк.
Для примера рассмотрим множество строк вида: Имя Фамилия. Естественным образом можно сказать, что шаблон вида
![]()
имеет некоторую семантическую значимость. Очевидно так же, что указанный выше шаблон не представляет полностью семантику множества строк указанных выше. Более того, для предложенного примера можно составить целое множество шаблонов, которые будут с тем или иным уровнем семантической значимости описывать множество указанных строк. Например:
![]()
![]()
![]()
![]()
и т.д.
Очевидно, что для множества строк, можно отыскать такой шаблон, которому будут удовлетворять все строки данного множества, однако при этом семантической значимости у этого шаблона будет не велика. Так например семантическая значимость шаблона вида ![]() будет гораздо меньше чем семантическая значимость шаблона вида
будет гораздо меньше чем семантическая значимость шаблона вида
![]() .
.
Любая реляционная база данных содержит некоторое множество атрибутов, а так же множество конкретных значений каждого атрибута [4]. Пусть ![]() - множество всех атрибутов базы данных. Пусть
- множество всех атрибутов базы данных. Пусть ![]() - множество значений атрибута
- множество значений атрибута ![]() ,
, ![]() - набор, множеств значений атрибутов, φ - некоторый шаблон. Рассмотрим функцию:
- набор, множеств значений атрибутов, φ - некоторый шаблон. Рассмотрим функцию:
![]() (6)
(6)
где ![]() - определенная выше функция, которая возвращает количество строк из множества
- определенная выше функция, которая возвращает количество строк из множества ![]() , которые удовлетворяют шаблону φ, а
, которые удовлетворяют шаблону φ, а ![]() - объем множества
- объем множества ![]() .
.
Функция ![]() дает численную оценку того, насколько точно шаблон описывает строки, которые принадлежат рассматриваемому домену. Значения функции лежат на отрезке [0, 1]. В дальнейшем эту величину будем кратко называть частотой появления шаблона φ на множестве
дает численную оценку того, насколько точно шаблон описывает строки, которые принадлежат рассматриваемому домену. Значения функции лежат на отрезке [0, 1]. В дальнейшем эту величину будем кратко называть частотой появления шаблона φ на множестве ![]() .
.
Определим функцию:
![]() (7)
(7)
где ![]() - набор множеств значений атрибутов. Указанная функция дает усредненное значение численной оценки того, насколько точно шаблон описывает строки, принадлежащие соответствующим множествам строк.
- набор множеств значений атрибутов. Указанная функция дает усредненное значение численной оценки того, насколько точно шаблон описывает строки, принадлежащие соответствующим множествам строк.
Определим функцию:
![]() (8)
(8)
где ![]() - множество значений i- го атрибута,
- множество значений i- го атрибута, ![]() - набор всех множеств значений атрибутов, кроме i- го. Значение функции тем выше, чем больше экземпляров множества i- го атрибута удовлетворяют шаблону φ и чем меньше среднее значение количества экземпляров остальных атрибутов удовлетворяющих шаблону. Значения функции лежат на отрезке [0, 1]. Максимальное значение функция принимает в том случае, когда все значения i- го атрибута удовлетворяют шаблону φ, и ни один экземпляр остальных атрибутов не удовлетворяет шаблону φ.
- набор всех множеств значений атрибутов, кроме i- го. Значение функции тем выше, чем больше экземпляров множества i- го атрибута удовлетворяют шаблону φ и чем меньше среднее значение количества экземпляров остальных атрибутов удовлетворяющих шаблону. Значения функции лежат на отрезке [0, 1]. Максимальное значение функция принимает в том случае, когда все значения i- го атрибута удовлетворяют шаблону φ, и ни один экземпляр остальных атрибутов не удовлетворяет шаблону φ.
Примем значение функции pV как численное выражение семантической значимости атрибута A относительно атрибутов ![]() в контексте шаблона φ.
в контексте шаблона φ.
Для множества шаблонов ![]() определим функцию семантической значимости, как среднее значение семантической значимости каждого шаблона в отдельности:
определим функцию семантической значимости, как среднее значение семантической значимости каждого шаблона в отдельности:
![]() (9)
(9)
Таким образом, множество шаблонов может считаться некоторой семантической характеристикой атрибута реляционной базы данных. Для построения такого множества необходимо решить задачу максимизации функции семантической значимости. Разработка метода решения такого рода задачи позволит автоматически строить семантическую характеристику атрибутов реляционных баз данных.
СПИСОК ЛИТЕРАТУРЫ:
- W. Hasselbring. Information system integration. //Communications of the ACM, 43(6)33-38, 2000.
- Цаленко М. Ш. Моделирование семантики в базах данных. - М.: Наука, 1989. - 287 c.
- Фридл Дж. Регулярные выражения, 2-е издание. - Спб.: Питер, 2003. - 464 с.
- Дейт К. Дж. Введение в системы баз данных, 7-е издание. - Пер. с англ. - М.: Издательский дом Вильямс, 2001. - 1072 c.
Библиографическая ссылка
Комар Ф.В. РАЗРАБОТКА МЕТОДА ОПИСАНИЯ СЕМАНТИКИ АТРИБУТОВ РЕЛЯЦИОННЫХ БАЗ ДАННЫХ // Успехи современного естествознания. 2008. № 3. С. 56-59;URL: https://natural-sciences.ru/ru/article/view?id=9578 (дата обращения: 15.06.2026).