


Scientific journal
Advances in current natural sciences
ISSN 1681-7494
"Перечень" ВАК
ИФ РИНЦ = 0,976
SOLUTION TASKS OF THE SECOND KIND WITH THE USE OF THE INFORMATION APPROACH

Обработка графической информации применяется в разных направлениях. Рассмотрим графическую информацию, которая получается при обработки графики с помощью сканирующих устройств и последующем переводе растровой информации в векторную. Эта задача часто решает в геоинформатике при цифровании карт и при обработке данных дистанционного зондирования и при формировании геоданных [1]. На практике применяют специализированные программы векторизаторы [2], которые решают большую часть задачи преобразования информации. Эти программы имеют специальные фильтры векторизации, которые настраивают процесс распознавания на определенный тип информации [3, 4], например чертежи, текст, деловая графика географические карты и т.д. Процесс векторизации является процессом трансформации информации [5] из одной формы в другую. На практике важна семантическая составляющая такого процесса [6]. Это касается вопросов информативности. Существующая практика оценки информативности часто связана с использованием энтропии и оценкой объема информационного объекта до и после обработки. В данной постановке задача информативности определяется по числу интерпретируемых объектов по отношению к исходным объектам.
Основная часть. Для проверки качества векторизации использовались четыре информационные коллекции. Информационная коллекция представляет собой совокупность однотипных объектов, которые легко сравнивать между до и после обработки. Эта совокупность позволяет набирать статистику.
Первая информационная коллекция включает регулярную сетку из 200 крестов с расстояниями между крестами 10мм и размером креста по вертикали и горизонтали 1,5 мм. Вторая информационная коллекция представляет собой совокупность 200 горизонтальных отрезков размером 1,5 мм. Третья информационная коллекция представляет собой совокупность 160 вертикальных отрезков размером 1,5 мм. Четвертый информационная коллекция представляет собой совокупность 160 окружностей диаметром 3 мм.
Использовались следующие параметры: N – количество объектов на входе до обработки; Ni – количество искаженных интерпретируемых объектов; Nl – количество потерянных объектов; No – количество неискаженных объектов на выходе; Nni – количество искаженных не интерпретируемых объектов;
Введены следующие коэффициенты Kl – коэффициент потерь; Kinf – коэффициент информативности; Kd – коэффициент искажений; Kint – коэффициент интерпретируемости искаженных объектов; К – коэффициент репрезентативности.
Kl = Nl / N; Kinf = (Ni + No)/ N; Kd = (Ni + Nni )/N;
Kint = Ni / (Ni + Nni); К= No / N.
Объект характеризуется количеством элементов и «характерной точкой». В качестве такой точки для симметричных объектов может быть центр симметрии. Для несимметричных объектов такой точкой может быть центроид. Объект считается искаженным, при изменении количества элементов в нем и при изменении положения характерной точки относительно других точек объекта. По существу речь идет о смещении точки. На рис. 1 приведены примеры характерных искажений. Характерная точка выделена штриховкой.
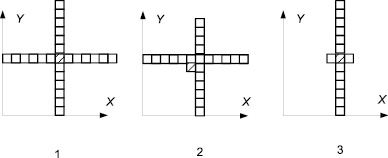
Рис. 1. Исходный объект и его искажения
Объект показан в целочисленных координатах, которые применяют при обработке растровых изображений. На рис. 1 под цифрой 1 показан исходный объект. Координаты его характерной точки в условной системе координат, показанной на рисунке равны X = 7, Y = 7.
Цифрой 2 показан объект с потерей двух элементов. Эта потеря приводи к смещению характерной точки. Координаты характерной точки в этом случае равны X = 6, Y = 6. Напомним, что в целочисленных системах координат нет дробной части. Это тип искажения называют асимметричным искажением.
Под цифрой 3 показан характерный объект, полученный при сканировании, когда направление сканирования или направление векторизации направлено вдоль оси Y. В этом случае иногда происходит потеря элементов на линиях перпендикулярных направлению сканирования. Симметрия сохраняется, но потеря элементов налицо. Это тип искажения называют симметричным искажением.
На рис. 2 приведена информационная ситуация [7, 8], характеризующая фрагмент первой информационной коллекции. Стрелкой показано направление сканирования или векторизации.
Информационные коллекции строятся по матричному типу. Это упрощает процедуру их кодирования и анализа. Цифры располагаются в порядке типичном для целочисленной системы координат. Таким образом, по фрагменту, характеризующему результаты обработки на рис. 2, можно сделать следующие выводы. Используем матричную кодировку объектов. Объект 1,7 потерян. Объекты 2,2; 1,3; 3,4; 2,5 – искажены. Все остальные объекты неискаженны. Количество искаженных интерпретируемых объектов Ni = 2. Это объекты 2,2 и 1,3. количество искаженных не интерпретируемых объектов Nni = 2. Это объекты 3, 4 и 2, 5.
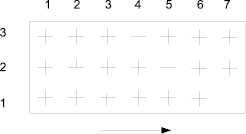
Рис. 2. Фрагмент информационной коллекции после обработки
Для информационной ситуации, показанной на рис. 2, имеем результаты, приведенные в табл. 1.
Таблица 1
Результаты оценки качества и информативности по макету
|
Качества |
Количественные характеристики |
|
N |
21 |
|
Nl |
1 |
|
Ni |
2 |
|
Nni |
2 |
|
No |
16 |
|
К |
0.76 |
|
Kl |
0.05 |
|
Kd |
0.19 |
|
Kinf |
0.86 |
Результаты полного исследования на четырех коллекциях приведены в табл. 2. Следует отметить, что кроме сканирования существует ряд алгоритмов обработки информации, которые также обрабатывают информацию построчно, это программы векторизаторы и программы построения цифровых моделей по методу развертывающей линии (sweepline algorithm) [9]. Поэтому результаты исследования и методика охватывают сканерную обработку и алгоритмическую обработку по тем же принципам.
Обсуждение. Коэффициент репрезентативности является основной характеристикой качества обработки информации. Он показывает, какая часть объектов сохраняет свои семантические и метрические свойства. Он же показывает, какая часть объектов сохраняет свой информационный объем. Коэффициент информативности является основной семантической характеристикой обработки информации. Он показывает, какая часть информации сохраняет содержательность, безотносительно к искажениям. Коэффициент интерпретируемости искаженных объектов является условной характеристикой. Он показывает, какая часть искаженных объектов сохраняет семантические свойства.
Таблица 2
Результаты оценки качества обработки на 4-х информационных коллекциях
|
Кол 1 |
Кол 2 |
Кол 3 |
Кол 4 |
|
|
N |
200 |
200 |
160 |
160 |
|
Nl |
22 |
28 |
0 |
0 |
|
Ni |
12 |
0 |
14 |
80 |
|
Nni |
12 |
16 |
16 |
8 |
|
No |
77 |
72 |
65 |
72 |
|
К |
0.77 |
0.72 |
0.81 |
45 |
|
Kl |
0.11 |
0.14 |
0.0 |
0 |
|
Kd |
0.12 |
0.08 |
0.23 |
0.55 |
|
Kinf |
0.83 |
0.72 |
0.9 |
0.95 |
|
Kint |
0.5 |
0.0 |
0.47 |
0.91 |
Рассмотренные элементарные объекты в теории САПР называют «графические примитивы». В семантической теории информации такие объекты являются информационными единицами [10, 11], а для графической информации «графическими информационными единицами».
Обобщенно данная методика сводится к следующему. Выбираются однородные наборы графических информационных единиц. Задается структура их расположения (локализация), что позволяет проводить дополнительный апостериорный контроль. Эти наборы образуют структурированную систему информационных единиц, или информационную коллекцию, которая пропускается через систему обработки (программа, устройство). Выходные данные поэлементно сравнивают с входными данными и вычисляют коэффициенты.
Данная методика применима для информационных коллекций с разным числом информационных единиц. Она позволяет проводить сравнение результатов обработки независимо от количества единиц.
Результаты, приведенные в табл. 2, дают основание предполагать, что направление сканирования или обработки объектов влияет на качество обработки и информативность Результаты, приведенные в таблице, дают основание предполагать, что существуют пространственные отношения [12] между направлением сканирования и качеством обработки информации. Результаты, приведенные в таблице, дают основание предполагать, что морфологически сложные информационные единицы информативно более устойчивы к преобразованиям, хотя менее устойчивы к искажениям, чем более простые информационные единицы. Это обусловлено тем, что в сложных информационных единицах существуют дополнительные связи между элементами этих единиц, которые повышают информационную устойчивость при обработке.
Результаты исследований дают основание ввести параметр «информационная устойчивость». Этот параметр определяет степень сохранения семантики информационной коллекции, информационной модели или информационной единицы при обработке. Этот параметр характеризует информационную коллекцию с одной стороны, с другой стороны характеризует систему обработки. Информационная устойчивость сложных информационных единиц выше за счет дополнительных связей, которые играют роль резервирования. Средство обработки информации имеет более высокое качество по сравнению с подобными, если оно обеспечивает высокую информационную устойчивость по сравнению с другими средствами на тех же информационных коллекциях.
Выводы
Данная методика применима для исследования различных графических образов в системах обработки. Она позволяет получать характеристики информационных коллекций и характеристики средств обработки. Результаты представляют интерес не только для технических приложений по физической обработке информации, но и для теоретических исследований в области пространственного знания. Информативность в данной методике, оценивается не по информационному объему, а по числу интерпретируемых объектов после обработки. Это основано на семантической теории информации. Исследование целесообразно расширить в область пространственного знания [13] и искусственного интеллекта [14].
Библиографическая ссылка
Цветков В.Я. ОЦЕНКА ИНФОРМАТИВНОСТИ И КАЧЕСТВА ОБРАБОТКИ ГРАФИЧЕСКОЙ ИНФОРМАЦИИ // Успехи современного естествознания. 2014. № 12-1. С. 137-140;URL: https://natural-sciences.ru/en/article/view?id=34500 (дата обращения: 13.07.2026).