



Рассмотрим следующую задачу. Требуется оценить уровень образования в различных Вузах. Так как уровень образования - это понятие достаточно абстрактное, то получить его точную количественную характеристику практически невозможно. Однако его можно косвенно оценить по ряду экономических показателей, характеризующих стоимость обучения, квалификацию преподавательского персонала, материально-техническую базу, имидж Вуза и т.д. Очень часто далее строят некоторый интегральный показатель, объединяющий в себе все частные показатели, и на его основе ранжируют объекты (в нашем случае Вузы) по уровню образования. Однако такой подход имеет два основных недостатка:
- Возможность компенсации низких значений одних показателей высокими значениями других. К примеру, если интегральный показатель равен простой сумме показателей, то Вуз, у которого стоимость обучения оценивается на 5, а качество подготовки на 3 будет эквивалентен Вузу, у которого стоимость обучения оценивается на 3, а качество обучения на 5. Это очевидно является абсурдным.
- Возможность наличия сильной корреляционной зависимости между показателями, что искажает получаемые результаты.
Таким образом, прямое измерение уровня образования с помощью интегрального показателя представляется нецелесообразным. Альтернативу этому способу составляет кластерный анализ, являющийся одним из способов многомерной классификации, который не измеряет уровень образования, но позволяет сформировать группы относительно однородных Вузов, которые экспертным путем можно будет в дальнейшем охарактеризовать как группы ВУзов соответственно с очень высоким, высоким, средним, низким и очень низким уровнем образования.
Итак, имеется совокупность n объектов, каждый из которых характеризуется по k замеренным на нем признакам. Требуется разбить эту совокупность на однородные в некотором смысле группы (классы). При этом практически отсутствует априорная информация о характере распределения измерений внутри классов.
Полученные в результате разбиения группы обычно называются кластерами, а также таксонами или образами. Методы нахождения кластеров называются кластерным анализом.
В задачах кластерного анализа обычной формой представления исходных данных служит прямоугольная таблица:

где xij- результат измерения j-го признака на i-ом объекте.
Наиболее трудным и наименее формализованным в задаче классификации является определение понятия однородности объектов. В общем случае понятие однородности объектов задается введением правила вычислений расстояния ![]() между любой парой исследуемых объектов. Близкие с точки зрения этой метрики объекты считаются однородными, принадлежащими одному классу. При этом необходимо сопоставлять полученные расстояния с некоторым пороговым значением, определяемым в каждом конкретном случае по-своему.
между любой парой исследуемых объектов. Близкие с точки зрения этой метрики объекты считаются однородными, принадлежащими одному классу. При этом необходимо сопоставлять полученные расстояния с некоторым пороговым значением, определяемым в каждом конкретном случае по-своему.
Рассмотрим наиболее часто используемые расстояния в задачах кластерного анализа.
- Обычное евклидово расстояние
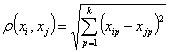
где ![]() - величина р-ой компоненты у i-го (j-го) объекта (
- величина р-ой компоненты у i-го (j-го) объекта (![]() ).
).
Естественно с геометрической точки зрения и содержательной интерпретации евклидово расстояние может оказаться бессмысленным, если его признаки имеют разные единицы измерения. Для приведения признаков к одинаковым единицам прибегают к нормировке каждого признака путем деления центрированной величины на среднее квадратическое отклонение и переходят от матрицы X к нормированной матрице с элементами
![]() ,
,
где ![]() - значение р-го признака у i-го объекта;
- значение р-го признака у i-го объекта; ![]() - среднее арифметическое значение р-го признака;
- среднее арифметическое значение р-го признака;
![]()
- среднее квадратическое отклонение р-го признака.
- «Взвешенное» евклидово расстояние
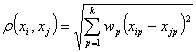
применяется в случаях, когда каждой компоненте xp удается приписать некоторый «вес» wp, пропорциональный степени важности признака в задаче классификации. Обычно принимают ![]() , где р=1,...,k.
, где р=1,...,k.
- Хеммингово расстояние
![]()
используется как мера различия объектов, задаваемых дихотомическими признаками, т.е. признаками, значения которых равны или 0, или 1. Хеммингово расстояние равно числу несовпадений значений соответствующих признаков в рассматриваемых объектах.
По мере того, как объекты объединяются в классы возникает необходимость измерения расстояния между этими классами. Наиболее употребительными расстояниями между классами объектов или кластерами являются:
1. расстояние, измеряемое по принципу «ближайшего соседа», т.е. расстояние между двумя ближайшими точками кластеров
![]()
2. расстояние, измеряемое по принципу «дальнего соседа», т.е. расстояние между двумя самыми дальними точками кластеров
![]()
3. расстояние, измеряемое по «центрам тяжести» групп
![]()
4. расстояние, измеряемое по принципу «средней связи» (Это расстояние определяется как среднее арифметическое всех попарных расстояний между представителями рассматриваемых групп)
![]()
Так как существует большое количество различных способов разбиения на классы заданной совокупности элементов, то представляет интерес задача сравнительного анализа качества этих способов разбиения. С этой целью вводится понятие функционала качества разбиения Q(S), определенного на множестве всех возможных разбиений.
Существуют следующие виды функционала качества:
1. сумма внутриклассовых дисперсий
![]()
2. сумма попарных внутриклассовых расстояний между элементами
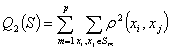
Иерархические кластер-процедуры
Иерархические (деревообразные) процедуры являются наиболее распространенными алгоритмами кластерного анализа. Они бывают двух типов: агломеративные и дивизимные.
Принцип работы иерархических агломеративных процедур состоит в последовательном объединении групп элементов сначала самых близких, а затем все более отдаленных друг от друга.
Принцип работы иерархических дивизимных процедур состоит в последовательном разделении групп элементов сначала самых далеких, а затем все более близких друг к другу.
Результаты
Поскольку кластерный анализ позволяет находить расстояние между объектами по любому количеству показателей, то целесообразной будет организация выбора их состава.
Расстояние между кластерами предлагается находить тремя способами. Это метод ближнего соседа, метод дальнего соседа и метод среднего значения.
В результате мы получим таблицу, в которой для каждого Вуза по указанным факторам будут даны оценки 6 экспертов, усредненные нами по весовым коэффициентам.
В результате получается ряд таблиц, представляющих собой все более укрупненное объединение Вузов в кластеры. Последней мы получаем таблицу 2 на 2, в которой все объекты разбиты на 2 кластера. В зависимости от цели исследования выбирается то или иное количество кластеров. Соответственно получается несколько групп однотипных Вузов. Для каждой группы необходимо разработать соответствующие рекомендации, отвечающие цели исследования.
Для сравнения с результатами, полученными при построении матрицы Мак-Кинси, рассмотрим в качестве факторов интегрированные показатели привлекательности и конкурентоспособности.
Кластерный анализ позволяет нам разделить объекты на требуемое количество групп вне зависимости от количества имеющихся у нас показателей, легко исключить ненужные показатели или связанные друг с другом, но для интерпретации результата, характеристики каждой группы необходимо применение каких-то других методов, чаще всего экспертных оценок. Именно поэтому матричный метод, в частности, построение матрицы Мак-Кинси, столь удобны, они позволяют не только разбить на группы (на 9 групп), но и получить наглядную характеристику объектов, попавших в ту или иную группу.